


On Friday, Google DeepMind introduced Robotic Transformer 2 (RT-2), a “first-of-its-kind” vision-language-action (VLA) mannequin that makes use of information scraped from the Web to allow higher robotic management by plain language instructions. The last word aim is to create general-purpose robots that may navigate human environments, just like fictional robots like WALL-E or C-3PO.
When a human desires to study a activity, we frequently learn and observe. In an analogous method, RT-2 makes use of a big language mannequin (the tech behind ChatGPT) that has been educated on textual content and pictures discovered on-line. RT-2 makes use of this data to acknowledge patterns and carry out actions even when the robotic hasn’t been particularly educated to do these duties—an idea known as generalization.
For instance, Google says that RT-2 can permit a robotic to acknowledge and throw away trash with out having been particularly educated to take action. It makes use of its understanding of what trash is and the way it’s often disposed to information its actions. RT-2 even sees discarded meals packaging or banana peels as trash, regardless of the potential ambiguity.

In one other instance, The New York Instances recounts a Google engineer giving the command, “Choose up the extinct animal,” and the RT-2 robotic locates and picks out a dinosaur from a choice of three collectible figurines on a desk.
This functionality is notable as a result of robots have usually been educated from an enormous variety of manually acquired information factors, making that course of troublesome as a result of excessive time and price of masking each potential situation. Put merely, the actual world is a dynamic mess, with altering conditions and configurations of objects. A sensible robotic helper wants to have the ability to adapt on the fly in methods which might be unimaginable to explicitly program, and that is the place RT-2 is available in.
Greater than meets the attention
With RT-2, Google DeepMind has adopted a method that performs on the strengths of transformer AI fashions, recognized for his or her capability to generalize data. RT-2 attracts on earlier AI work at Google, together with the Pathways Language and Picture mannequin (PaLI-X) and the Pathways Language mannequin Embodied (PaLM-E). Moreover, RT-2 was additionally co-trained on information from its predecessor mannequin (RT-1), which was collected over a interval of 17 months in an “workplace kitchen atmosphere” by 13 robots.
The RT-2 structure entails fine-tuning a pre-trained VLM mannequin on robotics and internet information. The ensuing mannequin processes robotic digital camera photos and predicts actions that the robotic ought to execute.
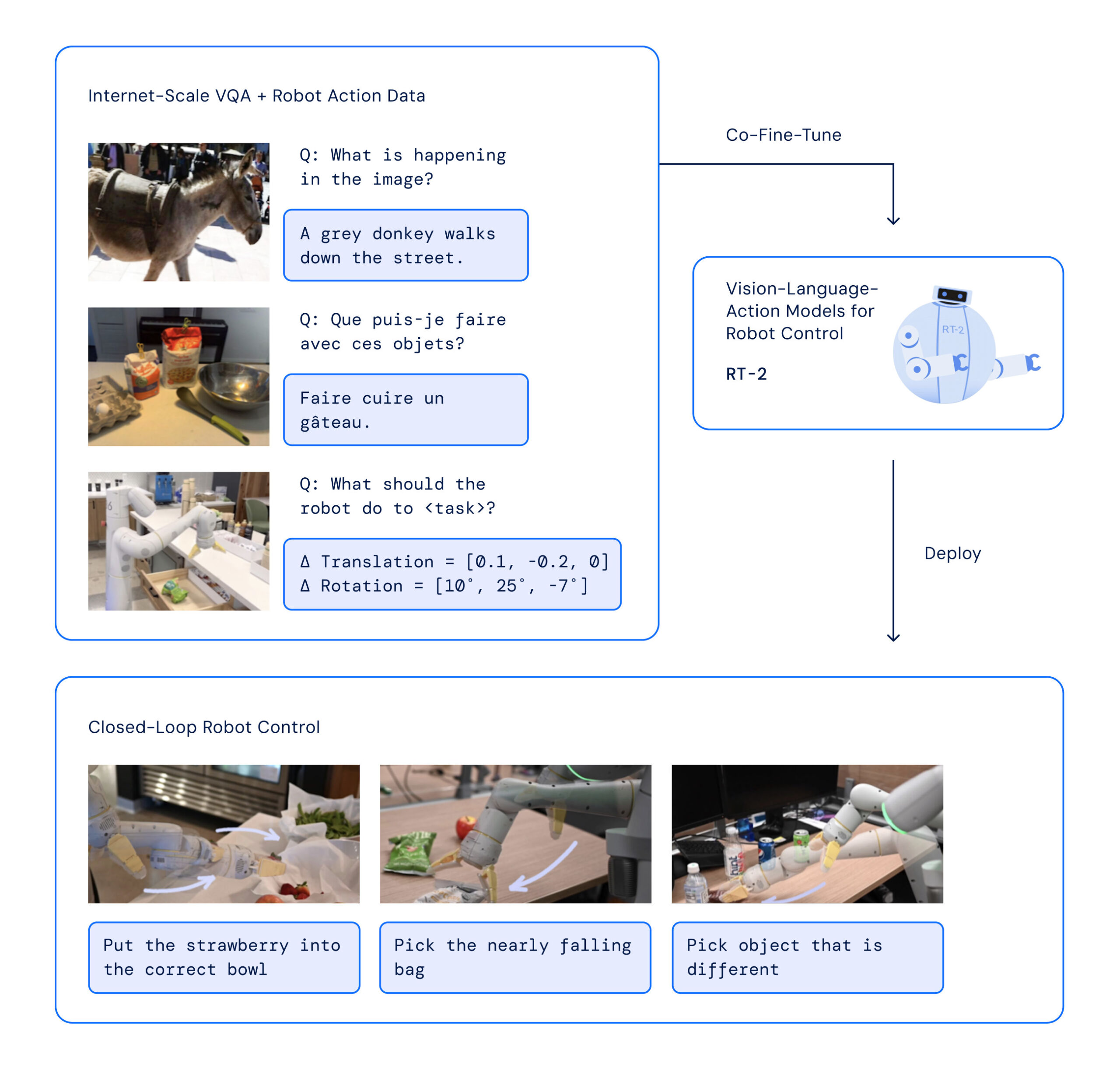
Since RT-2 makes use of a language mannequin to course of data, Google selected to signify actions as tokens, that are historically fragments of a phrase. “To manage a robotic, it have to be educated to output actions,” Google writes. “We tackle this problem by representing actions as tokens within the mannequin’s output—just like language tokens—and describe actions as strings that may be processed by customary pure language tokenizers.”
In creating RT-2, researchers used the identical methodology of breaking down robotic actions into smaller components as they did with the primary model of the robotic, RT-1. They discovered that by turning these actions right into a collection of symbols or codes (a “string” illustration), they may educate the robotic new expertise utilizing the identical studying fashions they use for processing internet information.
The mannequin additionally makes use of chain-of-thought reasoning, enabling it to carry out multi-stage reasoning like selecting an alternate software (a rock as an improvised hammer) or choosing the very best drink for a drained individual (an power drink).

Google says that in over 6,000 trials, RT-2 was discovered to carry out in addition to its predecessor, RT-1, on duties that it was educated for, known as “seen” duties. Nevertheless, when examined with new, “unseen” situations, RT-2 virtually doubled its efficiency to 62 % in comparison with RT-1’s 32 %.
Though RT-2 reveals an important capability to adapt what it has discovered to new conditions, Google acknowledges that it isn’t excellent. Within the “Limitations” part of the RT-2 technical paper, the researchers admit that whereas together with internet information within the coaching materials “boosts generalization over semantic and visible ideas,” it doesn’t magically give the robotic new skills to carry out bodily motions that it hasn’t already discovered from its predecessor’s robotic coaching information. In different phrases, it might probably’t carry out actions it hasn’t bodily practiced earlier than, nevertheless it will get higher at utilizing the actions it already is aware of in new methods.
Whereas Google DeepMind’s final aim is to create general-purpose robots, the corporate is aware of that there’s nonetheless loads of analysis work forward earlier than it will get there. However know-how like RT-2 looks as if a robust step in that path.



{kind=link}
On Friday, Google DeepMind introduced Robotic Transformer 2 (RT-2), a “first-of-its-kind” vision-language-action (VLA) mannequin that makes use of information scraped from the Web to allow higher robotic management by plain language instructions. The last word aim is to create general-purpose robots that may navigate human environments, just like fictional robots like WALL-E or C-3PO.
When a human desires to study a activity, we frequently learn and observe. In an analogous method, RT-2 makes use of a big language mannequin (the tech behind ChatGPT) that has been educated on textual content and pictures discovered on-line. RT-2 makes use of this data to acknowledge patterns and carry out actions even when the robotic hasn’t been particularly educated to do these duties—an idea known as generalization.
For instance, Google says that RT-2 can permit a robotic to acknowledge and throw away trash with out having been particularly educated to take action. It makes use of its understanding of what trash is and the way it’s often disposed to information its actions. RT-2 even sees discarded meals packaging or banana peels as trash, regardless of the potential ambiguity.
In one other instance, The New York Instances recounts a Google engineer giving the command, “Choose up the extinct animal,” and the RT-2 robotic locates and picks out a dinosaur from a choice of three collectible figurines on a desk.
This functionality is notable as a result of robots have usually been educated from an enormous variety of manually acquired information factors, making that course of troublesome as a result of excessive time and price of masking each potential situation. Put merely, the actual world is a dynamic mess, with altering conditions and configurations of objects. A sensible robotic helper wants to have the ability to adapt on the fly in methods which might be unimaginable to explicitly program, and that is the place RT-2 is available in.
Greater than meets the attention
With RT-2, Google DeepMind has adopted a method that performs on the strengths of transformer AI fashions, recognized for his or her capability to generalize data. RT-2 attracts on earlier AI work at Google, together with the Pathways Language and Picture mannequin (PaLI-X) and the Pathways Language mannequin Embodied (PaLM-E). Moreover, RT-2 was additionally co-trained on information from its predecessor mannequin (RT-1), which was collected over a interval of 17 months in an “workplace kitchen atmosphere” by 13 robots.
The RT-2 structure entails fine-tuning a pre-trained VLM mannequin on robotics and internet information. The ensuing mannequin processes robotic digital camera photos and predicts actions that the robotic ought to execute.
Since RT-2 makes use of a language mannequin to course of data, Google selected to signify actions as tokens, that are historically fragments of a phrase. “To manage a robotic, it have to be educated to output actions,” Google writes. “We tackle this problem by representing actions as tokens within the mannequin’s output—just like language tokens—and describe actions as strings that may be processed by customary pure language tokenizers.”
In creating RT-2, researchers used the identical methodology of breaking down robotic actions into smaller components as they did with the primary model of the robotic, RT-1. They discovered that by turning these actions right into a collection of symbols or codes (a “string” illustration), they may educate the robotic new expertise utilizing the identical studying fashions they use for processing internet information.
The mannequin additionally makes use of chain-of-thought reasoning, enabling it to carry out multi-stage reasoning like selecting an alternate software (a rock as an improvised hammer) or choosing the very best drink for a drained individual (an power drink).
Google says that in over 6,000 trials, RT-2 was discovered to carry out in addition to its predecessor, RT-1, on duties that it was educated for, known as “seen” duties. Nevertheless, when examined with new, “unseen” situations, RT-2 virtually doubled its efficiency to 62 % in comparison with RT-1’s 32 %.
Though RT-2 reveals an important capability to adapt what it has discovered to new conditions, Google acknowledges that it isn’t excellent. Within the “Limitations” part of the RT-2 technical paper, the researchers admit that whereas together with internet information within the coaching materials “boosts generalization over semantic and visible ideas,” it doesn’t magically give the robotic new skills to carry out bodily motions that it hasn’t already discovered from its predecessor’s robotic coaching information. In different phrases, it might probably’t carry out actions it hasn’t bodily practiced earlier than, nevertheless it will get higher at utilizing the actions it already is aware of in new methods.
Whereas Google DeepMind’s final aim is to create general-purpose robots, the corporate is aware of that there’s nonetheless loads of analysis work forward earlier than it will get there. However know-how like RT-2 looks as if a robust step in that path.