



On Monday, Mistral AI introduced a brand new AI language mannequin known as Mixtral 8x7B, a “combination of specialists” (MoE) mannequin with open weights that reportedly really matches OpenAI’s GPT-3.5 in efficiency—an achievement that has been claimed by others up to now however is being taken critically by AI heavyweights resembling OpenAI’s Andrej Karpathy and Jim Fan. Meaning we’re nearer to having a ChatGPT-3.5-level AI assistant that may run freely and domestically on our gadgets, given the appropriate implementation.
Mistral, based mostly in Paris and based by Arthur Mensch, Guillaume Lample, and Timothée Lacroix, has seen a speedy rise within the AI area lately. It has been shortly elevating enterprise capital to turn into a kind of French anti-OpenAI, championing smaller fashions with eye-catching efficiency. Most notably, some (however not all) of Mistral’s fashions run domestically with open weights that may be downloaded and used with fewer restrictions than closed AI fashions from OpenAI, Anthropic, or Google. (On this context “weights” are the pc information that symbolize a educated neural community.)
Mixtral 8x7B can course of a 32K token context window and works in French, German, Spanish, Italian, and English. It really works very similar to ChatGPT in that it will possibly help with compositional duties, analyze information, troubleshoot software program, and write applications. Mistral claims that it outperforms Meta’s a lot bigger LLaMA 2 70B (70 billion parameter) massive language mannequin and that it matches or exceeds OpenAI’s GPT-3.5 on sure benchmarks, as seen within the chart under.
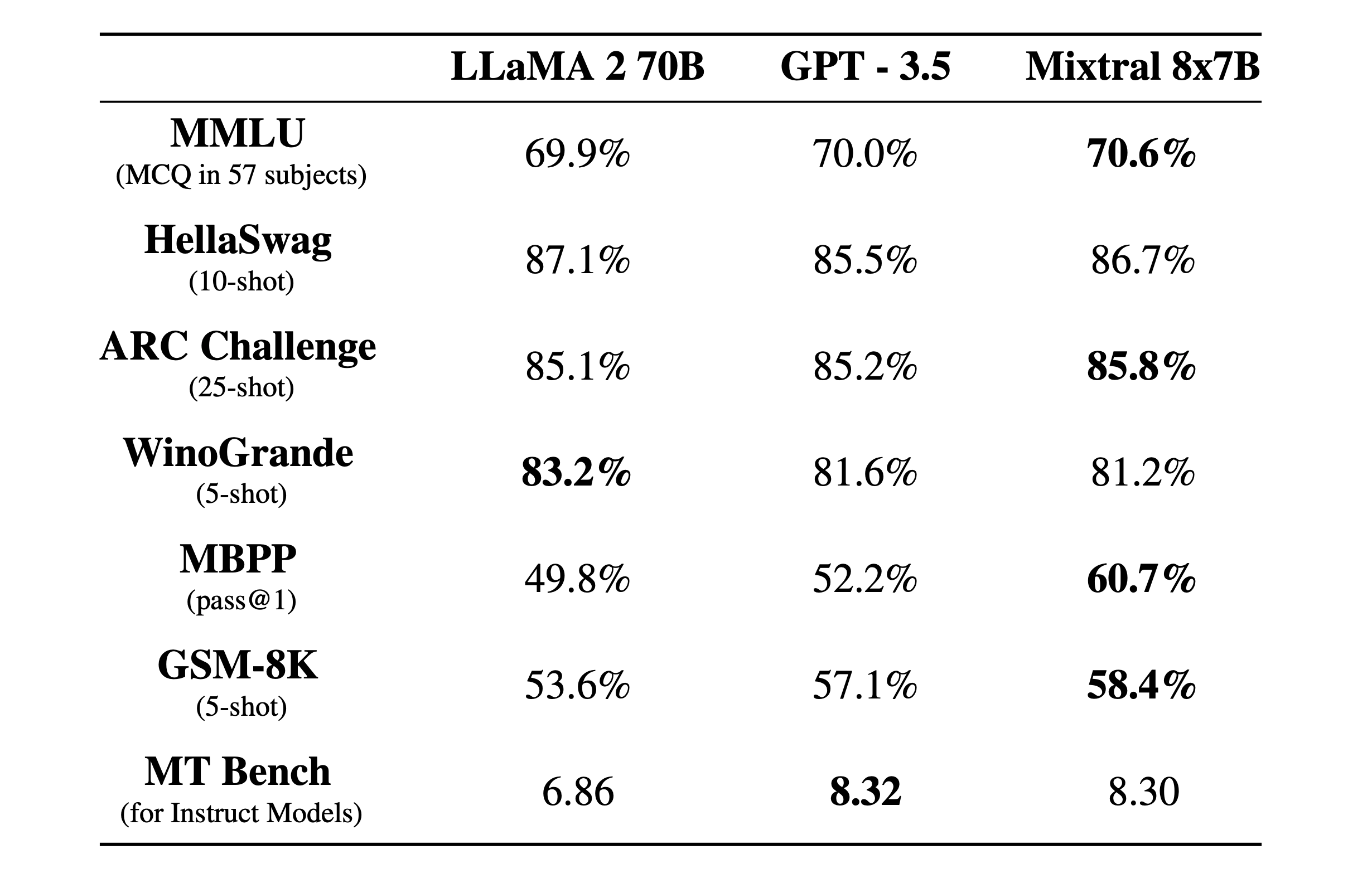
Mistral
The velocity at which open-weights AI fashions have caught up with OpenAI’s high providing a 12 months in the past has taken many unexpectedly. Pietro Schirano, the founding father of EverArt, wrote on X, “Simply unbelievable. I’m working Mistral 8x7B instruct at 27 tokens per second, fully domestically due to @LMStudioAI. A mannequin that scores higher than GPT-3.5, domestically. Think about the place we shall be 1 12 months from now.”
LexicaArt founder Sharif Shameem tweeted, “The Mixtral MoE mannequin genuinely looks like an inflection level — a real GPT-3.5 stage mannequin that may run at 30 tokens/sec on an M1. Think about all of the merchandise now doable when inference is 100% free and your information stays in your system.” To which Andrej Karpathy replied, “Agree. It looks like the aptitude / reasoning energy has made main strides, lagging behind is extra the UI/UX of the entire thing, possibly some device use finetuning, possibly some RAG databases, and so forth.”
Combination of specialists
So what does combination of specialists imply? As this glorious Hugging Face information explains, it refers to a machine-learning mannequin structure the place a gate community routes enter information to totally different specialised neural community elements, often known as “specialists,” for processing. The benefit of that is that it permits extra environment friendly and scalable mannequin coaching and inference, as solely a subset of specialists are activated for every enter, lowering the computational load in comparison with monolithic fashions with equal parameter counts.
In layperson’s phrases, a MoE is like having a group of specialised employees (the “specialists”) in a manufacturing unit, the place a sensible system (the “gate community”) decides which employee is finest suited to deal with every particular job. This setup makes the entire course of extra environment friendly and quicker, as every job is completed by an skilled in that space, and never each employee must be concerned in each job, in contrast to in a conventional manufacturing unit the place each employee might need to do a little bit of every part.



OpenAI has been rumored to make use of a MoE system with GPT-4, accounting for a few of its efficiency. Within the case of Mixtral 8x7B, the title implies that the mannequin is a mix of eight 7 billion-parameter neural networks, however as Karpathy pointed out in a tweet, the title is barely deceptive as a result of, “it’s not all 7B params which are being 8x’d, solely the FeedForward blocks within the Transformer are 8x’d, every part else stays the identical. Therefore additionally why complete variety of params will not be 56B however solely 46.7B.”
Mixtral is not the primary “open” combination of specialists mannequin, however it’s notable for its comparatively small measurement in parameter depend and efficiency. It is out now, accessible on Hugging Face and BitTorrent underneath the Apache 2.0 license. Individuals have been working it domestically utilizing an app known as LM Studio. Additionally, Mistral started providing beta entry to an API for 3 ranges of Mistral fashions on Monday.

{kind=link}
{kind=link}