


In contrast to standard LLMs, these SR fashions take further time to supply responses, and this further time typically will increase efficiency on duties involving math, physics, and science. And this newest open mannequin is popping heads for apparently rapidly catching as much as OpenAI.
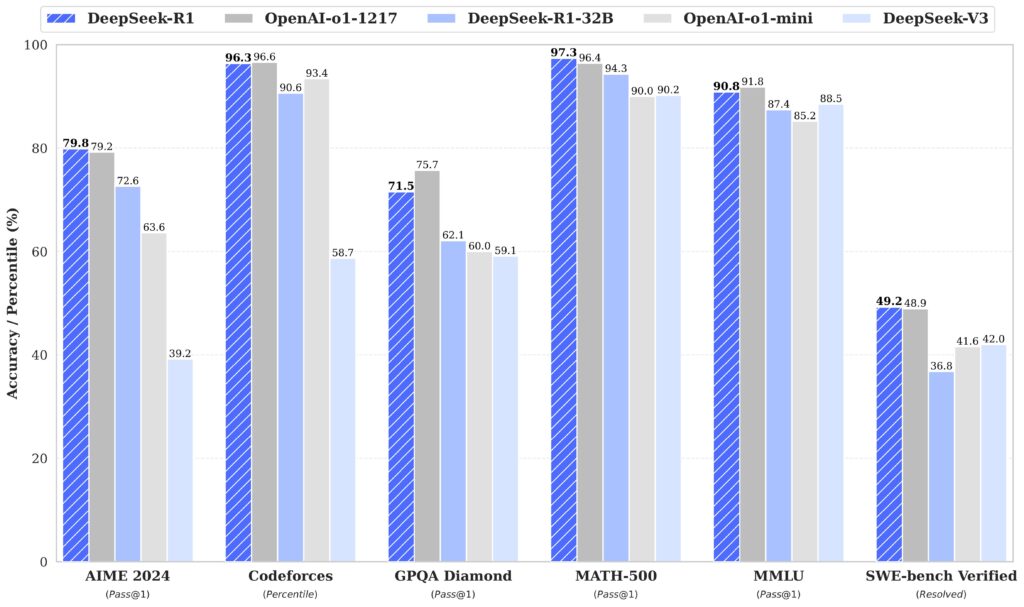
For instance, DeepSeek experiences that R1 outperformed OpenAI’s o1 on a number of benchmarks and exams, together with AIME (a mathematical reasoning check), MATH-500 (a set of phrase issues), and SWE-bench Verified (a programming evaluation instrument). As we often point out, AI benchmarks must be taken with a grain of salt, and these outcomes have but to be independently verified.
TechCrunch experiences that three Chinese language labs—DeepSeek, Alibaba, and Moonshot AI’s Kimi—have now launched fashions they are saying match o1’s capabilities, with DeepSeek first previewing R1 in November.
However the brand new DeepSeek mannequin comes with a catch if run within the cloud-hosted model—being Chinese language in origin, R1 won’t generate responses about sure matters like Tiananmen Sq. or Taiwan’s autonomy, because it should “embody core socialist values,” in keeping with Chinese language Web laws. This filtering comes from an extra moderation layer that is not a problem if the mannequin is run regionally exterior of China.
Even with the potential censorship, Dean Ball, an AI researcher at George Mason College, wrote on X, “The spectacular efficiency of DeepSeek’s distilled fashions (smaller variations of r1) signifies that very succesful reasoners will proceed to proliferate broadly and be runnable on native {hardware}, removed from the eyes of any top-down management regime.”



In contrast to standard LLMs, these SR fashions take further time to supply responses, and this further time typically will increase efficiency on duties involving math, physics, and science. And this newest open mannequin is popping heads for apparently rapidly catching as much as OpenAI.
For instance, DeepSeek experiences that R1 outperformed OpenAI’s o1 on a number of benchmarks and exams, together with AIME (a mathematical reasoning check), MATH-500 (a set of phrase issues), and SWE-bench Verified (a programming evaluation instrument). As we often point out, AI benchmarks must be taken with a grain of salt, and these outcomes have but to be independently verified.
TechCrunch experiences that three Chinese language labs—DeepSeek, Alibaba, and Moonshot AI’s Kimi—have now launched fashions they are saying match o1’s capabilities, with DeepSeek first previewing R1 in November.
However the brand new DeepSeek mannequin comes with a catch if run within the cloud-hosted model—being Chinese language in origin, R1 won’t generate responses about sure matters like Tiananmen Sq. or Taiwan’s autonomy, because it should “embody core socialist values,” in keeping with Chinese language Web laws. This filtering comes from an extra moderation layer that is not a problem if the mannequin is run regionally exterior of China.
Even with the potential censorship, Dean Ball, an AI researcher at George Mason College, wrote on X, “The spectacular efficiency of DeepSeek’s distilled fashions (smaller variations of r1) signifies that very succesful reasoners will proceed to proliferate broadly and be runnable on native {hardware}, removed from the eyes of any top-down management regime.”

{kind=link}