

Anomaly detection is the method of figuring out information factors or patterns in a dataset that deviate considerably from the norm. A time collection is a group of knowledge factors gathered over a while. Anomaly detection in time collection information could also be useful in varied industries, together with manufacturing, healthcare, and finance. Anomaly detection in time collection information could also be achieved utilizing unsupervised studying approaches like clustering, PCA (Principal Element Evaluation), and autoencoders.
What’s an Anomaly Detection Algorithm?
Anomaly detection is the method of figuring out information factors that deviate from the anticipated patterns in a dataset. Many functions, together with fraud detection, intrusion detection, and failure detection, usually use anomaly detection methods. Discovering unusual or very rare occasions that might level to a potential hazard, challenge, or alternative is the goal of anomaly detection.
The autoencoder algorithm is an unsupervised deep studying algorithm that can be utilized for anomaly detection in time collection information. The autoencoder is a neural community that learns to reconstruct its enter information By first compressing enter information right into a lower-dimensional illustration after which extending it again to its unique dimensions. An autoencoder could also be skilled on typical time collection information to be taught a compressed model of the information for anomaly identification. The anomaly rating might then be calculated utilizing the reconstruction error between the unique and reconstructed information. Anomalies are information factors with appreciable reconstruction errors.
Time Sequence Knowledge and Anamoly Detection
Within the case of time collection information, anomaly detection algorithms are particularly necessary since they assist us spot odd patterns within the information that will not be apparent from simply wanting on the uncooked information. Anomalies in time collection information would possibly seem as abrupt will increase or lower in values, odd patterns, or surprising seasonality. Time collection information is a group of observations throughout time.
- Time collection information could also be used to show anomaly detection algorithms, such because the autoencoder, the best way to symbolize typical patterns. These algorithms can then make the most of this illustration to search out anomalies. The method can be taught a compressed model of the information by coaching an autoencoder on common time collection information. The anomaly rating might then be calculated utilizing the reconstruction error between the unique and reconstructed information. Anomalies are information factors with appreciable reconstruction errors.
- Anomaly detection algorithms could also be utilized to time collection information to search out odd patterns that might level to a hazard, challenge, or alternative. For example, within the context of predictive upkeep, a time collection anomaly might level to a potential gear failure which may be fastened earlier than it ends in a considerable amount of downtime or security issues. Anomalies in time collection information might reveal market actions or patterns in monetary forecasts which may be capitalized on.
The rationale for getting precision, recall, and F1 rating of 1.0 is that the “ambient_temperature_system_failure.csv” dataset from the NAB repository comprises anomalies. If we had gotten precision, recall, and F1 rating of 0.0, then meaning the “ambient_temperature_system_failure.csv” dataset from the NAB repository doesn’t include anomalies.
Importing Libraries and Dataset
Python libraries make it very straightforward for us to deal with the information and carry out typical and complicated duties with a single line of code.
- Pandas – This library helps to load the information body in a 2D array format and has a number of capabilities to carry out evaluation duties in a single go.
- Numpy – Numpy arrays are very quick and might carry out massive computations in a really quick time.
- Matplotlib/Seaborn – This library is used to attract visualizations.
- Sklearn – This module comprises a number of libraries having pre-implemented capabilities to carry out duties from information preprocessing to mannequin improvement and analysis.
- TensorFlow – That is an open-source library that’s used for Machine Studying and Synthetic intelligence and gives a variety of capabilities to attain complicated functionalities with single traces of code.
Python3
|
On this step, we import the libraries required for the implementation of the anomaly detection algorithm utilizing an autoencoder. We import pandas for studying and manipulating the dataset, TensorFlow and Keras for constructing the autoencoder mannequin, and scikit-learn for calculating the precision, recall, and F1 rating.
Python3
|
We load a dataset known as “ambient_temperature_system_failure.csv” from the Numenta Anomaly Benchmark (NAB) dataset, which comprises time-series information of ambient temperature readings from a system that skilled a failure.
The panda’s library is used to learn the CSV file from a distant location on GitHub and retailer it in a variable known as “information”.
- Now, the code drops the “timestamp” column from the “information” variable, since it isn’t wanted for information evaluation functions. The remaining columns are saved in a variable known as “data_values”.
- Then, the “data_values” are transformed to the “float32” information kind to cut back reminiscence utilization, and a brand new pandas DataFrame known as “data_converted” is created with the transformed information. The columns of “data_converted” are labeled with the unique column names from “information”, apart from the “timestamp” column that was beforehand dropped.
- Lastly, the code provides the “timestamp” column again to “data_converted” in the beginning utilizing the “insert()” methodology. The ensuing DataFrame “data_converted” has the identical information as “information” however with out the pointless “timestamp” column, and the information is in a format that can be utilized for evaluation and visualization.
Python3
|
We take away any lacking or NaN values from the dataset.
Anomaly Detection utilizing Autoencoder
It’s a kind of neural community that learns to compress after which reconstruct the unique information, permitting it to establish anomalies within the information.
Python3
|
We outline the autoencoder mannequin and match it to the cleaned information. The autoencoder is used to establish any deviations from the common patterns within the information which are discovered from the information. To scale back the imply squared error between the enter and the output, the mannequin is skilled. The reconstruction error for every information level is decided utilizing the skilled mannequin and is utilized as an anomaly rating.
Python3
|
Right here, we outline an anomaly detection threshold and assess the mannequin’s effectiveness utilizing precision, recall, and F1 rating. Recall is the ratio of true positives to all actual positives, whereas precision is the ratio of real positives to all projected positives. The harmonic imply of recall and accuracy is the F1 rating.
Python3
|
Output:
Precision: 1.0 Recall: 1.0 F1 Rating: 1.0
Visualizing the Anomaly
Now let’s plot the anomalies that are predicted by the mannequin and get a really feel for whether or not the predictions made are right or not by plotting the anomalous examples with crimson marks with the whole information.
Python3
|
Output:
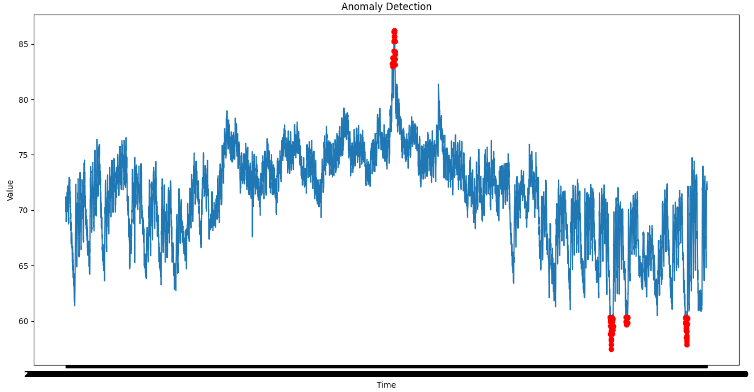
Anomaly represented with crimson dots on time collection information
Final Up to date :
09 Jun, 2023
Like Article
Save Article


