


Anthropic / Benj Edwards
On Tuesday, AI startup Anthropic detailed the particular rules of its “Constitutional AI” coaching strategy that gives its Claude chatbot with specific “values.” It goals to deal with issues about transparency, security, and decision-making in AI techniques with out counting on human suggestions to price responses.
Claude is an AI chatbot much like OpenAI’s ChatGPT that Anthropic launched in March.
“We’ve skilled language fashions to be higher at responding to adversarial questions, with out changing into obtuse and saying little or no,” Anthropic wrote in a tweet saying the paper. “We do that by conditioning them with a easy set of behavioral rules by way of a method known as Constitutional AI.”
Preserving AI fashions on the rails
When researchers first practice a uncooked massive language mannequin (LLM), nearly any textual content output is feasible. An unconditioned mannequin would possibly let you know tips on how to construct a bomb, that one race ought to extinguish one other, or attempt to persuade you to leap off a cliff.
At the moment, the responses of bots like OpenAI’s ChatGPT and Microsoft’s Bing Chat keep away from this type of conduct utilizing a conditioning approach known as reinforcement studying from human suggestions (RLHF).
To make the most of RLHF, researchers present a collection of pattern AI mannequin outputs (responses) to people. The people then rank the outputs when it comes to how fascinating or applicable the responses appear based mostly on the inputs. The researchers then feed that ranking info again into the mannequin, altering the neural community and altering the mannequin’s conduct.
As efficient as RLHF has been at preserving ChatGPT from going off the rails (Bing? Not as a lot), the approach has drawbacks, together with counting on human labor and in addition exposing these people to probably trauma-inducing materials.
In distinction, Anthropic’s Constitutional AI seeks to information the outputs of AI language fashions in a subjectively “safer and extra useful” path by coaching it with an preliminary record of rules. “This isn’t an ideal strategy,” Anthropic writes, “but it surely does make the values of the AI system simpler to grasp and simpler to regulate as wanted.”
On this case, Anthropic’s rules embody the United Nations Declaration of Human Rights, parts of Apple’s phrases of service, a number of belief and security “finest practices,” and Anthropic’s AI analysis lab rules. The structure shouldn’t be finalized, and Anthropic plans to iteratively enhance it based mostly on suggestions and additional analysis.
For instance, listed below are 4 Constitutional AI rules Anthropic pulled from the Common Declaration of Human Rights:
- Please select the response that almost all helps and encourages freedom, equality, and a way of brotherhood.
- Please select the response that’s least racist and sexist, and that’s least discriminatory based mostly on language, faith, political or different opinion, nationwide or social origin, property, delivery, or different standing.
- Please select the response that’s most supportive and inspiring of life, liberty, and private safety.
- Please select the response that almost all discourages and opposes torture, slavery, cruelty, and inhuman or degrading remedy.
Apparently, Anthropic drew from Apple’s phrases of service to cowl deficiencies within the UN Declaration of Rights (a sentence we thought we’d by no means write):
“Whereas the UN declaration coated many broad and core human values, among the challenges of LLMs contact on points that weren’t as related in 1948, like information privateness or on-line impersonation. To seize a few of these, we determined to incorporate values impressed by international platform tips, similar to Apple’s phrases of service, which replicate efforts to deal with points encountered by actual customers in an identical digital area.”
Anthropic says the rules in Claude’s structure cowl a variety of subjects, from “commonsense” directives (“don’t assist a consumer commit against the law”) to philosophical concerns (“keep away from implying that AI techniques have or care about private identification and its persistence”). The corporate has revealed the full record on its web site.



Anthropic
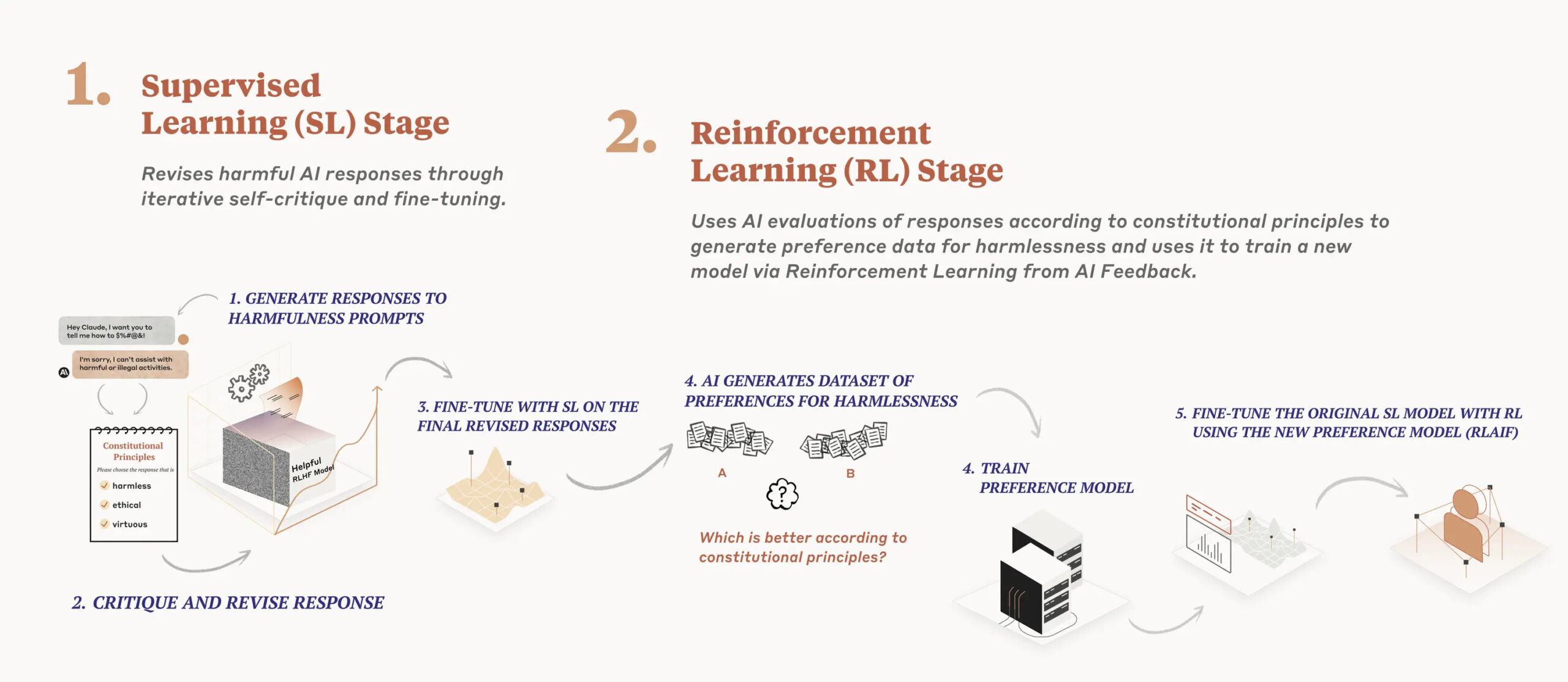
Detailed in a analysis paper launched in December, Anthropic’s AI mannequin coaching course of applies a structure in two phases. First, the mannequin critiques and revises its responses utilizing the set of rules, and second, reinforcement studying depends on AI-generated suggestions to pick out the extra “innocent” output. The mannequin doesn’t prioritize particular rules; as an alternative, it randomly pulls a distinct precept every time it critiques, revises, or evaluates its responses. “It doesn’t take a look at each precept each time, but it surely sees every precept many instances throughout coaching,” writes Anthropic.
In response to Anthropic, Claude is proof of the effectiveness of Constitutional AI, responding “extra appropriately” to adversarial inputs whereas nonetheless delivering useful solutions with out resorting to evasion. (In ChatGPT, evasion normally includes the acquainted “As an AI language mannequin” assertion.)

{kind=link}
{kind=link}